
The initial fascination with generative AI usually follows a predictable arc: a user types a prompt, receives a stunning image, and feels a momentary sense of creative omnipotence. However, for teams attempting to move beyond isolated social media posts and into serious production—storyboarding, brand campaigns, or long-form video—that feeling quickly evaporates. The “slot machine” nature of text-to-image models becomes a liability. You can generate a perfect character once, but generating that same character in a different pose, under different lighting, or within a moving video sequence remains one of the most significant technical hurdles in the current creative landscape.
Professional utility in AI isn’t found in the ability to generate a single “cool” image; it is found in the ability to maintain identity stability. This stability is the difference between an amateur experiment and a commercially viable asset pipeline. To achieve it, creators are moving away from the “magic button” mindset and toward a disciplined, multi-stage workflow that utilizes technical anchors and specific model environments.
The Drift Problem: Why Generative Identity Fails by Default
At the heart of the consistency struggle is a concept known as “latent space drift.” When you prompt an AI model, it navigates a multi-dimensional map of visual concepts to find a point that matches your description. The problem is that even a minor variation in your prompt—changing “standing in a forest” to “sitting in a cafe”—shifts the mathematical starting point of the generation. Because the model is biased toward novelty and aesthetic “pleasingness” rather than strict anatomical or facial fidelity, the character’s bone structure, hair texture, and even eye color can shift between frames.
For marketers, this drift is a deal-breaker. Brand equity is built on recognition. If your digital spokesperson or mascot looks like a slightly different person in every ad, the “uncanny valley” effect takes over. The viewer stops focusing on the message and starts subconsciously trying to reconcile the shifting visual identity. Standard text-to-image workflows are inherently disorganized; they treat every generation as a blank slate. To combat this, operators must impose external structure onto the model’s internal randomness.
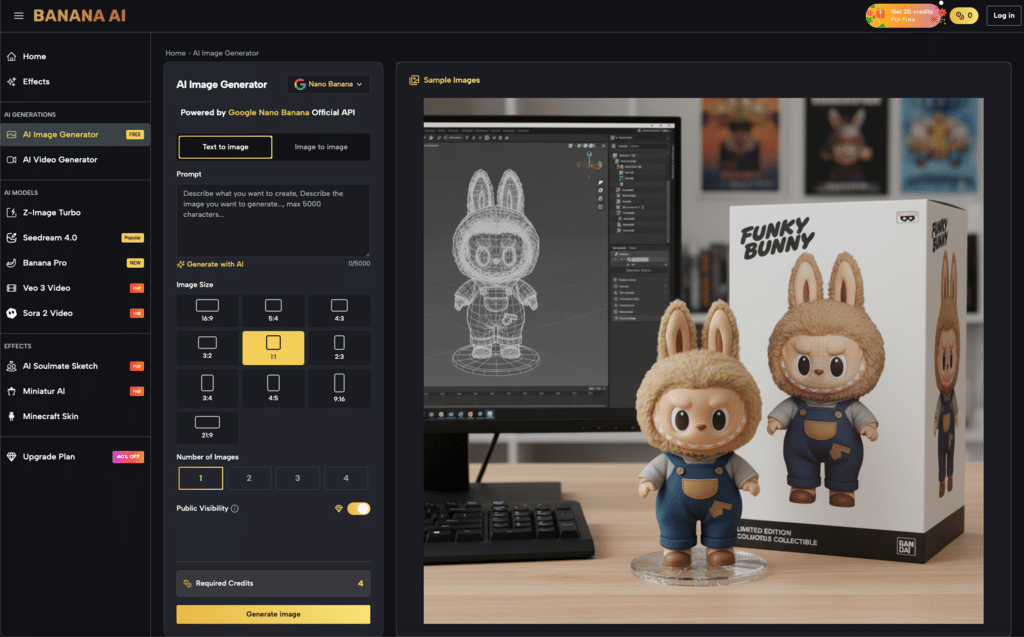
Technical Anchors and the Utility of Model Specificity
The first step in stabilizing identity is selecting an environment that allows for granular control. Generic, consumer-facing apps often hide the technical parameters that make consistency possible. Advanced platforms like Banana AI Image provide access to specialized models such as Seedream 4.0 and Banana Pro, which are designed with higher prompt adherence in mind.
The most critical tool in this stage is seed management. Every AI-generated image begins as a field of random noise, and the “seed” is the number that determines the specific pattern of that noise. If you find a character you like, the first thing you must do is lock the seed. By using the same seed across multiple generations with only slight prompt adjustments, you provide the model with a “mathematical starting point” that remains constant. This significantly reduces the variance in facial morphology, though it is not a perfect fix.
On Banana AI Image, the workflow shifts from guessing to iterating. By documenting the exact prompt tokens that define a character’s “identity”—specific descriptors for nose shape, jawline, or distinct clothing—and combining them with a fixed seed, teams can produce a “character sheet” of static images. This sheet serves as the source of truth for all subsequent content, ensuring that the character remains recognizable across different environments.
Bridging the Gap from Static Frame to Motion
Consistency challenges scale exponentially when moving from static images to video. In a text-to-video workflow, the AI is essentially hallucinating 24 to 30 new images every second. Without a strong visual anchor, the subject will “melt” or morph into different versions of themselves as they move through a scene.
The most reliable way to maintain identity in video is to bypass text-to-video entirely in favor of an Image-to-Video workflow. This technique uses a pre-existing, high-fidelity static image as the first frame of the video. When using the video tools within Banana AI, the model (such as Veo 3 Video) uses the initial image as a structural blueprint. Rather than trying to figure out what the character looks like from a text description, the model only has to figure out how that specific, already-defined subject should move.
This “first-frame anchor” method is the current gold standard for character-driven stories. It allows the creator to spend as much time as necessary perfecting the character’s look in a static environment before committing to the computational expense of video generation. If the static character is verified as brand-compliant, the resulting video has a much higher chance of maintaining that compliance throughout the duration of the clip.
The Limits of Control: Navigating Current Technical Boundaries
It is important to reset expectations regarding what is currently possible. Despite the advancements in models like Banana Pro, we are not yet at a point where a “one-click” solution exists for perfect, high-motion character consistency.
One major limitation involves temporal stability during complex physical actions. If you ask an AI character to perform a 360-degree spin or engage in rapid, fine-motor hand movements, the model often loses track of the subject’s geometry. You might see a “phantom limb” or a sudden change in hair length mid-rotation. Current generative architectures still struggle to understand 3D physical permanence; they are essentially predicting the next most likely pixel, not simulating a physical body in space.
Another area of uncertainty is lighting consistency across vastly different environments. While you can maintain a character’s face, the AI will often struggle to realistically reflect local light sources—like a neon sign or a sunset—onto that face without also altering the character’s features. In these high-stakes commercial scenarios, manual post-production or “inpainting” remains a necessary final step. AI can do 90% of the heavy lifting, but the final 10% of precision usually requires human intervention to fix artifacts or subtle identity drifts.
Architecting a Repeatable Asset Pipeline
For teams looking to integrate these tools into their daily operations, a tactical, step-by-step approach is more effective than erratic experimentation. A repeatable pipeline for identity stability generally follows a three-stage process:
- The Reference Frame: Generate your “hero” image. This should be a high-resolution, front-facing or three-quarter view of your subject. Use a model like Seedream 4.0 on Banana AI Image to ensure high detail. Document the seed and the specific “identity tokens” in your prompt.
- Seed-Locked Variation: Use the Image-to-Image feature to create the character in different poses or outfits. By keeping the denoising strength low and the seed fixed, you can generate a library of assets where the character remains consistent while the context changes.
- Video Interpolation: Take your best static variations and run them through the Image-to-Video engine in Banana AI. This ensures that the motion is derived from a stable visual source rather than a vague text prompt.
When evaluating which tools to bring into a professional workflow, the focus should not be on which tool produces the “prettiest” single image. Instead, look for tools that offer visibility into seeds, support for image-to-image referencing, and high-quality video models like Veo 3.
The goal for any creator or marketer is to move from being a “prompter” to being an “operator.” A prompter hopes for a good result; an operator builds a system that guarantees one. By focusing on subject and scene continuity through technical anchors, teams can finally treat AI not as a novelty, but as a reliable extension of their creative production suite. While the technology still has its friction points—particularly in high-motion scenes—the transition from random generation to disciplined identity management is already yielding professional-grade results for those willing to do the logistical legwork.







